Link to paper The full paper is available here.
You can also find the paper on PapersWithCode here.
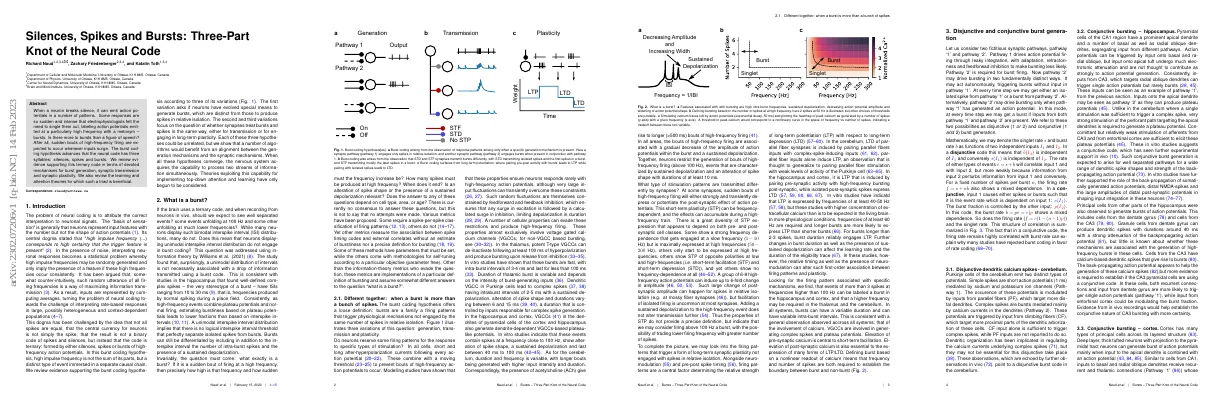
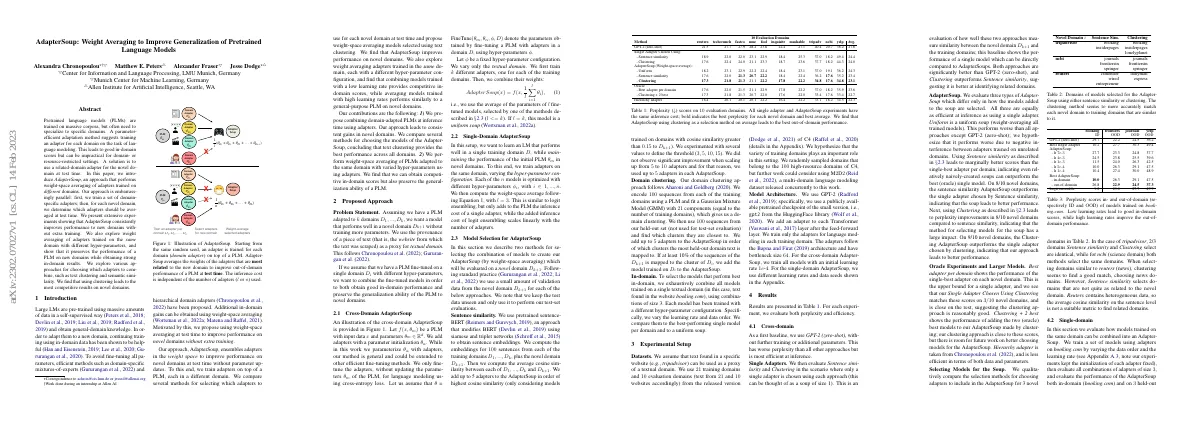
Abstract Molecular conformation generation (MCG) is an important problem in drug discovery Traditional methods have been developed to solve MCG, such as systematic searching, model-building, random searching, etc. Recently, deep learning based MCG methods have been developed A simple and cheap algorithm (parameter-free) based on traditional methods is comparable to or even outperforms deep learning based MCG methods Code of the proposed algorithm is available online Paper Content Introduction Molecular conformation generation is important for drug discovery It is related to many drug design tasks Traditional MCG uses conformational search and energy minimization RDKit is a popular cheminformatics software Distance geometry and direct coordinate methods are used Diffusion models are also used Deep learning models are evaluated with Coverage and Matching A simple algorithm based on traditional approaches outperforms deep learning models Related work Classical methods in computational chemistry Development of deep learning Data-driven solutions proposed by researchers Classical methods Traditional MCG paradigm involves conformational search, energy minimization, and energy evaluation Conformational search problem is a combinatorial explosion problem Popular conformational search methods include system search, random search, model-building, distance geometry, and molecular dynamics Energy evaluation methods include force field and electronic structure methods Force field methods are less accurate than electronic structure methods, but are faster Deep learning methods Deep learning methods outperform traditional methods on the GEOM benchmark Earlier work used VAE to generate atomic coordinates directly, but it could not maintain translation and rotation equivariance Later works use intermediate structures such as interatomic distances or torsion angles to generate conformations Diffusion models have been applied to the conformation generation task Method Proposed a method based on RDKit with clustering post-processing Used three samplers to generate diverse and low-energy conformations Applied unsupervised cluster algorithm to select conformations with consideration of diversity and energy Sampled with uniform, geometric, and energy samplers in the ratio of 1:1:4 Experiment Datasets and setup used for benchmarking 10 competitive baselines compared Results show method outperforms most baselines Ablation study conducted to demonstrate more diverse conformations can easily achieve better results Benchmarking should be done according to requirements of downstream applications Conclusion Algorithm outperforms deep learning models Suggest community rethink benchmark in MCG Deep learning can help build effective MCG models RDKit + Clustering algorithm proposed Performance on GEOM-QM9 and GEOM-Drugs Ablation studies for number of samples and sampler type on GEOM-QM9