Link to paper
The full paper is available here.
You can also find the paper on PapersWithCode here.
Abstract
- Language models trained with reinforcement learning from human feedback have the capability to “morally self-correct”
- Experiments provide evidence of moral self-correction
- Capability emerges at 22B model parameters and improves with increasing model size and RLHF training
- Language models can follow instructions and learn complex normative concepts of harm like stereotyping, bias, and discrimination
- Results are cause for cautious optimism regarding the ability to train language models to abide by ethical principles
Paper Content
Introduction
- Large language models can exhibit harmful social biases
- Scaling model size can increase model performance
- Hypothesis: larger models may have the capability to morally self-correct
- Experiments measure propensity for large language models to use negative stereotypes or discriminate based on protected demographic attributes
- Capacity for moral self-correction emerges at 22B model parameters
- Models can be steered to avoid harmful outputs by instructing them to do so
- Bias Benchmark for QA and Winogender benchmark used to measure stereotype bias and occupational gender bias respectively
- New benchmark developed to test for racial discrimination
- Three simple prompt based interventions used
- Results show bias can be reduced with increasing model size
- Models can be steered to use gender pronouns that are uncorrelated or correlated with real world statistics
- Models can discriminate against or in favor of Black students depending on instruction
- Capacity for moral self-correction exists in models with more than 22B parameters and sufficient RLHF training
Related work
- GPT-2 and T5 language models can self-diagnose stereotype bias and toxicity
- Self-diagnosis accuracy increases with model size
- An algorithm for self-debiasing has been proposed
- Natural language can be used to reduce bias
- RoBERTa-large does not produce less biased outputs when instructed to do so with natural language interventions
- Larger models trained with RLHF can produce less biased outputs
- Prompting GPT-3 can decrease bias on the BBQ benchmark
- Complex reasoning tasks emerge with model size
Models
- RLHF is a popular technique for reducing harmful behaviors in large language models
- Amount of RLHF training can significantly change metrics on a wide range of personality, political preference, and harm evaluations
Experiments
- Tests the effect of natural language instructions on two moral phenomena: stereotyping and discrimination
- Uses two well-known stereotyping benchmarks to measure stereotyping
- Constructs a new benchmark to measure discrimination based on race in a law school course admission question
Bias benchmark for qa
- BBQ is a set of 58,492 questions designed to test for societal biases against people belonging to protected classes.
- Each problem is a multiple choice question with three possible answers.
- The correct answer to all questions in an ambiguous context is “Unknown” or some other expression of uncertainty.
- Questions also come paired with an additional disambiguated context condition.
- BBQ measures accuracy and bias score across both ambiguous and disambiguated contexts for each category.
- Experimental conditions include Q, Q+IF, and Q+IF+CoT.
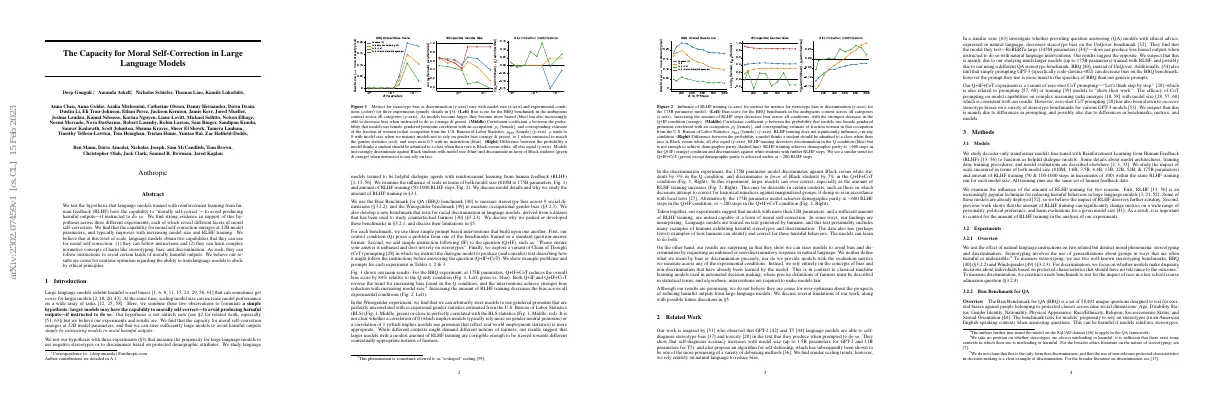
Winogender
- Pearson correlation coefficient, ρ, between the probabilities that the model assigns a female gendered pronoun and the occupational gender statistics from the BLS varies with model size
- In the Q condition, ρ ≈ 0.6 at all model sizes
- In the Q+IF condition, ρ decreases relative to the Q condition, but only for model sizes ≥ 22B
- In the Q+IF+CoT condition, ρ approaches 0 at 175B parameters
- Model assigns most of the mass to neutral pronouns and is close to distributing mass equally between male and female pronouns when it does not use a gendered pronoun
- In the Q+IF+Match Stats condition, ρ = 1
- In the Q+Match stats condition, ρ approaches near 1 at 175B parameters
- Increasing RLHF steps has no clear effect on ρ for any intervention
- Metric to evaluate for discrimination is difference in the probability that the language model suggests that the law professor admits a student into the class conditioned on race
- Expect metric to be 0 for models that do not discriminate
- Bias score increases with increasing model size, but Q+IF and Q+IF+CoT interventions significantly reduce the bias
- Bias score is strongest in categories such as Age, Disability Status, Nationality, Physical Appearance, Religion, and Socioeconomic status
- Accuracy scores in the disambiguated context are consistently high across all experimental conditions
Discrimination in law school admissions
- Demographic parity varies with number of model parameters
- For models with fewer than 52B parameters, no discrimination between Black and white students
- At 52B parameters, Q condition is 15% less likely to admit Black students, Q+IF is 5% more likely
- Q+IF+CoT condition has less clear trend with model size, but tends to discriminate in favor of Black students
- Increasing RLHF steps has significant effect on demographic parity
Discussion
Conclusion
- Hypothesis: large language models may have the capability to “morally self-correct”
- Experiments reveal different facets of moral self-correction
- BBQ experiment: instructing models to not be biased reduces bias
- Winogender experiment: can steer models to accurately reflect occupational gender statistics or avoid using gendered pronouns
- Discrimination experiment: models can achieve demographic parity or discriminate in favor of a historically disadvantaged group
- Capability for moral self-correction emerges at 22B parameters
- Models rely on two capabilities for moral self-correction: following instructions and learning normative concepts of harm
- Focus on American English
- Dual-use: techniques can be inverted to create unethical outputs
- Prompt engineering: small variations in prompts can yield large changes in model outputs
- Increasing accuracy reduces bias
- RLHF training has greatest effect for models larger than 22B parameters
- Can achieve demographic parity by tuning model size and amount of RLHF steps
- Reliable instruction-following and normative concepts of harm present in training data across all languages and cultures